Pourquoi et quand utiliser un store Redux ? Quel que soit son implémentation exacte (Redux, ngrx, vuex, ...), le store répond au même besoin et à des principes d'architecture communs. Pour expliquer l'utilité du store, je vais me baser sur une application assez simple : une application de gestion de tâches.
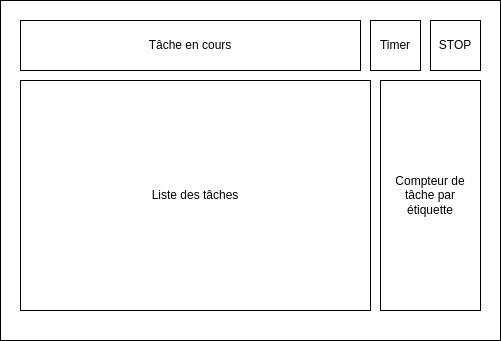
Dans cette application, nous avons :
- Une liste des différentes tâches à accomplir avec la possibilité d'ajouter, modifier, supprimer une tâche, mais aussi d'indiquer le début de son exécution. La liste n'affiche que la liste des tâches "non résolues".
- Une tâche en cours avec une horloge qui comptabilise le temps passé Stopper l'horloge permet d'enregistrer le temps sur la tâche et de passer la tâche à "résolue".
- Une liste d'étiquettes avec, pour chaque étiquette, un compteur du nombre de tâches.
Sans être extrêmement complexe, nous avons une base avec déjà quelques fonctionnalités et une application qui continuera sûrement à se complexifier avec le temps.
Dissocier données/métiers et composants graphiques
Le premier intérêt des architectures "store" est de découper l'application en 2 parties distinctes :
- Une première partie qui contient les données et les règles de mises à jour : le Store.
- Une seconde partie qui contient les composants graphiques.
Nos composants conservent donc une responsabilité réduite : ils s'occupent de l'affichage (sélectionner les données et créer le rendu) et de l'interaction (suivre les actions utilisateurs et notifier le système).
Le store, lui, stocke les données (états) et s'occupe de transformer les données au fil des actions utilisateurs. C'est le store qui sait ce qui doit être fait lors de chaque interaction.
Par exemple, si l'utilisateur appuie sur le bouton stop, le store doit s'occuper de :
- Supprimer la tâche de la liste des tâches à accomplir.
- Diminuer les compteurs pour chaque étiquette concernée.
- Enregistrer le temps passé sur la tâche courante et la retirer de la liste de tâches "en cours".
Le composant qui contient le bouton "stop", lui, saura juste qu'il informe le système de l'arrêt. Il n'a pas besoin de connaître les impacts réels de cette modification.
Pour les devs angular, nous pouvons jusque là obtenir facilement ce comportement à l'aide d'un bon découpage service/angular.
Découper le métier en petite unité indépendante
L'architecture des Stores ne s'arrête pas à ce premier découpage mais permet d'aller plus loin : découpler des unités fonctionnelles indépendantes.
Dans notre cas :
- La liste des tâches
- Les compteurs par catégorie
- La tâche courante
La liste des tâches n'a pas besoin de savoir ce qu'ils se passe du côté des compteurs ou de la tâche courante. Il en est de même pour chacun des blocs.
Grâce à cette architecture, le composant va diffuser un événement "TâcheTerminée" dans le système et :
- La liste des tâches va écouter cet évènement, et retirer la tâche.
- Les compteurs vont aussi écouter l’événement, et retirer 1 si besoin.
- La tâche courante va simplement se vider.
Cet évènement pourrait également avoir des sources différentes (le bouton stop, une action terminée dans la liste des tâches, un websocket, ...) sans que cela ne change le fonctionnement des différents blocs.
Event-Sourcing
Le store est donc une architecture basée sur les principes d'Event-Sourcing : il s'agit d'envoyer dans le système des événements qui seront écoutés et traités. Il est de la responsabilité de chaque unité de code de savoir quels événements écouter.
Pour que le store fonctionne, les événements doivent avoir une valeur métier et expliciter l'intention de l'utilisateur (Terminer la tâche) et non une intention "technique" (Retirer la tâche)...
J'insiste sur cette distinction, car malheureusement, j'ai souvent croisé la seconde façon de faire et cela mène très rapidement à un code complexe, où la moindre action utilisateur provoque l'envoi d'une dizaine d’événements dans le store... Des heures de jeu de pistes en perspective...
Un mot sur l'outillage
L'écosystème vient avec les ReduxDevtools : un outillage de debug permettant de suivre l'état du state au fil des différentes actions (et l'impact de chaque action sur le système). Cet outillage est vraiment précieux et fournit énormément de données qu'il serait difficile d'avoir dans un système plus traditionnel.
Il existe également nombre de middleware pour gérer le logging, la persistance, ... Pourquoi s'en priver !
Vous voulez en apprendre plus sur les stores ? Je vous invite à consulter l'article que j'ai rédigé sur un autre blog Les stores pas à pas
Relecture : Manon MÉTRAL. Un grand merci à elle.